Deze post is origineel verschenen op Mark’s eigen blog.
Over de titel: oordeel zelf na het lezen. U vindt het misschien vreemd om statistiek te doen op een blog, maar zeg niet dat dit niet kan. Ik laat de beide blogs lezen door een willekeurige steekproef van 1000 mensen en vraag ze een cijfer geven voor beide blogs (oei, confronterend). Ik ga u nu niet lastigvallen met hoe we dan significantie berekenen. P-waardes, betrouwbaarheidsintervallen, posterior kansen; en welk afkappunt te gebruiken: voer voor vele statistische discussies. Nee, het gaat mij hier om de context van het gedane vergelijk. Ik geef u vier voorbeelden.
Small World: dit blog is significant beter dan mijn vorige
Medium World: de blogs (of columns) van Ionica Smeets zijn significant beter dan de mijne
Big World: de blogs van wiskundigen zijn significant beter dan die van andere wetenschappers
Whole World: de blogs van wetenschappers zijn significant beter dan die van niet-wetenschappers
Me vs Ionica
Zoals ik al aangaf: het Small World vergelijk is eenvoudig te toetsen. Als maar genoeg mensen beide blogs lezen (dat zou mooi zijn!), kunnen we de bewering nauwkeurig toetsen. De significantie is echter van zeer beperkte waarde: alleen voor mij geeft het relevante info, en dan nog beperkt, bij gebrek aan referentiepunt. Het Medium World vergelijk is al interessanter. Voor mij, omdat Ionica Smeets een goed referentiepunt is. Maar ook voor potentiële lezers met weinig tijd: als het waar is, kunnen zij besluiten alleen de stukjes van Ionica te lezen )-: . Maar nu wordt het lastig. Je zou zeggen dat dit vergelijk ook eenvoudig te toetsen is: laat de stukjes van Ionica en die van mij ook door 1000 mensen scoren. Dan heb je weer genoeg data om de bewering te toetsen. Ai, dit gaat helaas niet op. Waarom niet? We moeten nog beslissen hoeveel stukjes van Ionica en mij we laten scoren. Ionica is niet het probleem: zij heeft genoeg stukjes geschreven. Dat probleem ben ik. Ik heb pas vijf blogs geschreven. Prima toch, dan laat je iedereen die 5 stukjes lezen en 5 willekeurige stukjes van Ionica, en klaar ben je: maar liefst 1000 * 5 * 2 data punten. Moet genoeg zijn toch? Nee. De echte steekproefgrootte is namelijk niet 10,000, maar 5. En dat is echt te weinig om tot een significantie-uitspraak te komen over al onze blogs, ook diegenen die nog niet geschreven zijn. Want stel: mijn 6e stukje is briljant (stel hè). Dan zijn die eerste 5 dus geen goede representatie van ‘al mijn stukjes’. Met die 6e erbij zou de conclusie mogelijk veranderen.
In de Big en Whole Worlds geldt hetzelfde principe, maar dan weer een niveau hoger. Om een nauwkeurige uitspraak te doen over significantie, hebben we niet zozeer veel blogs en beoordelaars nodig, maar vooral blogs van veel verschillende wiskundigen, andere wetenschappers en niet-wetenschappers. Nu is het vergelijken van blogs niet de meest wetenschappelijke exercitie. Maar ook in de wetenschap is de ene significantie de andere niet. Variaties op het volgende voorbeeld kom ik tijdens mijn werk zeker een paar keer per jaar tegen.
Muizencellen
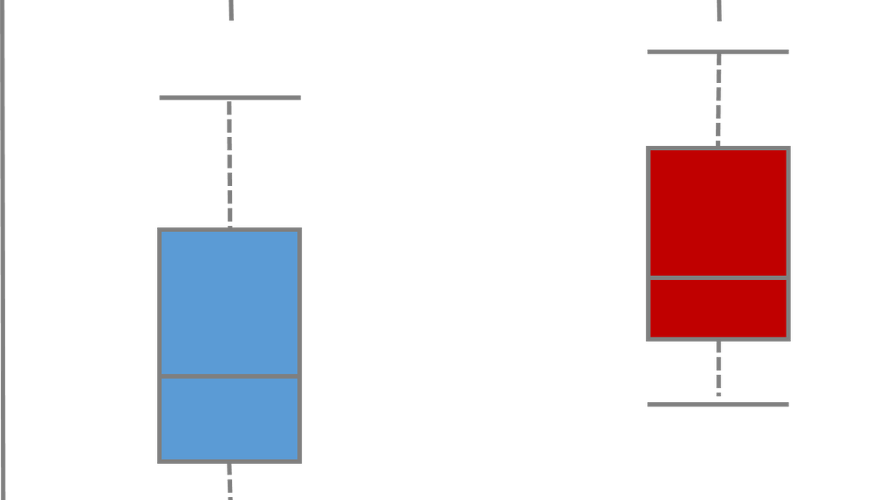
Team A heeft een stofje dat kankercellen moet doden. Ze isoleren veel, zeg 1000, cellen uit één muis. 500 cellen krijgen het stofje, 500 andere cellen niet. Van de eerste groep gaan heel veel cellen dood, in de 2e groep maar weinig: yes, een supersignificant verschil! Publiceren die hap. Team B wil dit reproduceren, maar ook iets nieuws doen. Daarom doen ze het experiment in triplo, dus op 3 muizen. Slechts 3, want goedkoop is het niet. Met de data komt Team B bij mij. Ik doe netjes een ‘herhaalde metingen’ analyse, welke rekening houdt met de twee niveau’s van variatie: de cellen en de muizen. En ai, nu is het resultaat helemaal niet significant. Team B is verbouwereerd, want ze hebben zelfs drie keer zo veel data dan Team A! De crux ligt ‘m in wat ‘significant’ betekent bij de resultaten van Team A. Omdat maar één muis is gebruikt, kan Team A alleen concluderen dat voor deze specifieke muis het stofje een effect heeft. En dus niet voor de populatie muizen in het algemeen. Helaas wordt dit er meestal niet bij gezegd als we de sterretjes boven een figuur zien. Bij de analyse voor Team B ligt de ambitie hoger: we willen een uitspraak doen voor de hele populatie muizen, niet alleen voor deze drie. Dat kan nu omdat we herhalingen hebben. Maar helaas zijn dat er slechts drie, dus hoeveel cellen je ook meet per muis: de effectieve steekproefgrootte is eigenlijk heel klein.
Draag uw steentje bij
Zorg dus dat u genoeg herhalingen hebt op het niveau waarop u een uitspraak wilt doen. Dus ik moet meer blogs schrijven en Team B moet meer muizen doormeten. Tot slot: ik daag u uit een steentje bij te dragen aan dit blog. Geef hier uw mening over welk blog beter was: dit of het vorige over de avondklok. Ik beloof u: ik kom er op terug (als het aantal responders > 10, want anders is dit experiment mislukt).











Add comment