
Publicaties die scholen of verschillende groepen leerlingen vergelijken, kunnen op veel aandacht rekenen. Dit gebeurde voor het eerst toen Jaap Dronkers, hoogleraar onderwijssociologie, van 1997 tot 2012 de scholenranglijsten in dagblad Trouw presenteerde. Men stortte zich jaarlijks massaal op deze overzichtelijk gemaakte hitlijst van beste tot slechtste scholen. Tegenwoordig komen telkens meer onderwijsgegevens beschikbaar die geanalyseerd kunnen worden. Om onderwijs te onderzoeken met deze grote onderwijsdatasets moet je bedenken wat precies de vraag is en welke vergelijkingen je kunt maken om deze vraag te beantwoorden. In het recente verleden zette het gebruik van een niet goed uitgedachte vergelijkende maatstaaf het voortgezet onderwijs een tijd lang op een verkeerd been. Ook bij de nieuwe onderwijsrapportages is het niet altijd duidelijk wat de gekozen vergelijkingen en maatstaven nu eigenlijk betekenen.
Aandacht voor de standaard
Voor Dronkers waren gestandaardiseerde toetsen zoals het centraal examen en de citotoets de echte graadmeters om scholen te kunnen vergelijken. Hij vond het dus niet zo interessant of bijvoorbeeld de slagingspercentages op een school goed waren, die werden namelijk beïnvloed door de resultaten op de schoolexamens. Het was voor Dronkers vooral interessant of op een school de cijfers op de schoolexamens hoger dan wel lager waren dan de cijfers op het centraal examen. Deze manier van redeneren heeft zo zijn weerslag op het onderwijs gehad.
Effect op de onderwijspraktijk
Hoe de ophef over verschillen tussen schoolexamen en centraal examencijfers doordrong tot de onderwijspraktijk kan ik ook uit eigen ervaring vertellen. Als scheikundedocent op een categoriaal gymnasium besprak ik eens de examenresultaten met de schoolleiding. De rector merkte hierbij op dat de cijfers op de schoolexamens bij onze sectie duidelijk lager waren dan die op het centraal examen. Een aandachtspuntje: mogelijk zouden wij hiermee onze (gymnasium)leerlingen benadelen t.o.v. de rest van Nederland.
In deze periode sprak ik op een conferentie ook een scheikundedocent van een andere school. Hij gaf aan (voor zijn gevoel gaf hij waarschijnlijk toe) dat hij dit jaar helaas ‘weer te hoog zat met zijn schoolexamencijfers’ en dus strenger zou moeten gaan beoordelen. In die tijd was namelijk het algemene beeld dat docenten met hogere gemiddelde cijfers op het schoolexamen dan op het centraal examen watjes waren die geen hoge eisen durfden te stellen aan leerlingen.
Eigen onderzoek aan verschilscores
Getriggerd door het belang dat werd toegekend aan de verschil-score tussen de cijfers op het schoolexamen en het centraal examen keek ik eens met wat meer aandacht naar de cijfers in mijn eigen examenklassen. Het viel mij op dat er een vreemde, maar duidelijke trend was in de verschil-score tussen centraal examen- en schoolexamencijfers. Naarmate de leerlingen hogere cijfers haalden op het schoolexamen gingen ze gemiddeld nog hogere cijfers halen op het centraal examen.
Toen ik mijn bevindingen deelde, was de eerste vraag of ik niet gewoon naar regressie naar het gemiddelde aan het kijken was. Maar dat was het juist niet. De trend van schoolexamen- naar centraal examencijfers was juist regressie van het gemiddelde af en dus niet naar het gemiddelde toe. De verklaring bleek te liggen in de verdeling van cijfers: op het centraal examen was deze breder dan op het schoolexamen. Eén van de oorzaken hiervoor is in ieder geval dat het schoolexamen altijd is opgebouwd uit een middeling van meerdere cijfers, waardoor uitschieters minder voorkomen. Hieronder laat ik zien hoe onder deze conditie van een bredere cijferverdeling op het centraal examen dan het schoolexamen, bij zowel perfecte correlatie (1) als geen correlatie (0) de verschilscore tot stand komt. Onder beide uiterste condities (en ook voor die met alle tussenliggende correlaties) is de trend dat bij scholen met een hoger centraal examengemiddelde het schoolexamengemiddelde lager is en dat voor scholen met een lager centraal examengemiddelde het schoolexamengemiddelde juist hoger is.
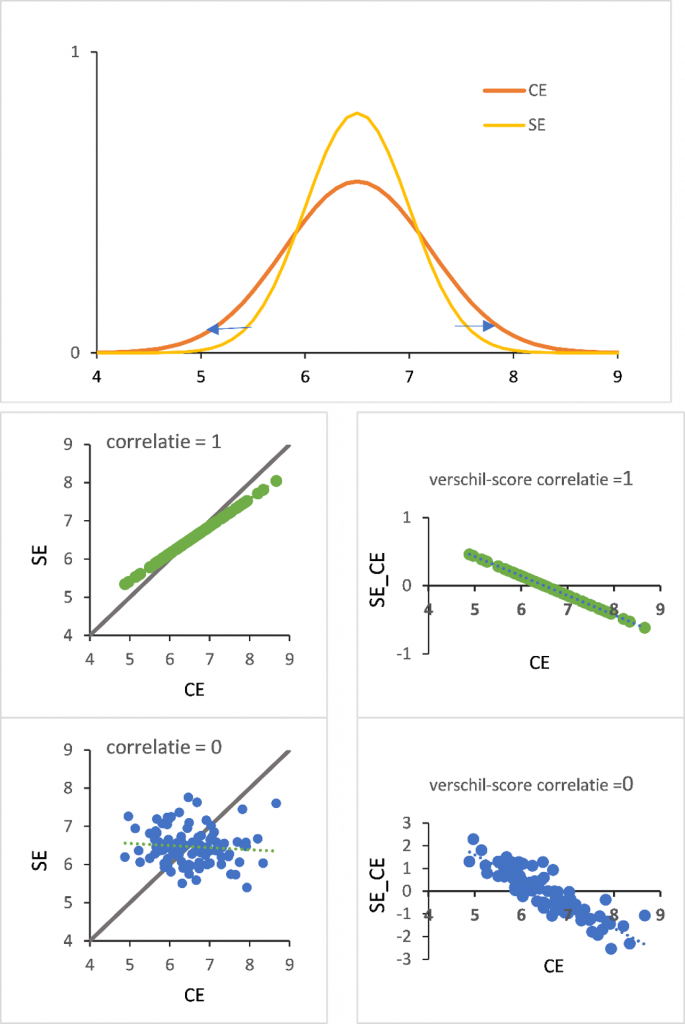
Bovenstaande simulatie heeft als enige input de gemiddelden en de standaarddeviaties van de twee verdelingen. Je kunt op deze manier ook de verschillen in verschil-scores tussen scholen goed beschrijven (zie hoe statistiek het schoolexamen verdacht maakte). Wat Dronkers als een alarmerend signaal zag was dus juist een volstrekt logisch gevolg van dat de cijfers breder verdeeld zijn op het centraal dan op het schoolexamen.
Nieuwe onderwijsrapportages
Tegenwoordig kunnen basis- en middelbare scholen voor van alles en nog wat een terugkoppeling krijgen over hoe ze het doen in vergelijking tot andere scholen. Dit gaat via gepersonaliseerde (privé)schoolrapportages die door het nationaal cohort onderwijsonderzoek (NCO) worden opgesteld (zie voor voorbeeldrapportages www.nationaalcohortonderzoek.nl/rapportages).
Voor ieder schoolniveau worden ongeveer 25 indicatoren gerapporteerd, zoals: gemiddelde eindtoetsscores, hoeveel leerlingen doorstromen naar vmbo, havo en vwo, hoe vaak leerlingen blijven zitten, hoe vaak ze in niveau op- en afstromen, gemiddelde examencijfers en hoe de onderwijsloopbaan verder gaat bij de volgende opleiding. Hoe groot het verschil is tussen de cijfers op het schoolexamen en het centraal examen bij de vakken Nederlands, Engels en wiskunde (wat dus eigenlijk een weinig zeggende indicator is , zie boven) ontbreekt ook niet. Het idee is dat scholen van al deze vergelijkingen iets leren over de invloed van hun onderwijs op de resultaten van hun leerlingen.
Voorspelde referentiewaarde
Om scholen ‘eerlijk’ te kunnen vergelijken, schat NCO wat de verschillen in de achtergronden van de leerlingen en algemene kenmerken van de school zelf voor invloed hebben op de onderwijsuitkomsten. Hiertoe berekent NCO voorspelde referentiewaarden, waarmee iedere school haar eigen unieke set van referentieniveaus krijgt. Dit gebeurt aan de hand van meervoudige lineaire regressie met achtergrondkenmerken, zoals inkomen van de ouders, migratieachtergrond, en gezinssamenstelling. Het opleidingsniveau van de ouders wordt nog niet meegenomen in de analyses, omdat deze informatie onvoldoende beschikbaar is om op schoolniveau mee te nemen. Hierdoor ontbreekt de sterkst voorspellende factor voor het schoolsucces van leerlingen in de analyse. Dit zou op zich niet zo erg hoeven zijn als men alleen in de uitkomst van de voorspelde referentiewaarde geïnteresseerd was. Zo wordt het echter niet gepresenteerd.
Valse associaties
Als een verklarende variabele (‘opleidingsniveau ouders’) ontbreekt in zo’n analyse die de voorspelde referentiewaarde berekent, hangt de uitkomst sterker af van variabelen die wel zijn meegenomen in het model. Dit betekent echter niet dat die variabelen er ook écht toe doen. Misschien hebben ze alleen een verband met een variabele die er wél echt toe doet, maar die ontbreekt in het model. Ik bekeek dit in de landelijke onderwijsdatabase van NCO. Zo ontdekte ik dat een aantal zeer sterke relaties, zoals de afhankelijkheid van het diplomaniveau van de leerling als functie van het inkomen ouders, zo goed als verdween wanneer de vergelijking binnen hetzelfde opleidingsniveau van de ouders gemaakt werd (Zie Nationaal Cohortonderzoek moet kansenongelijkheid in het onderwijs anders meten.)
Nu staan naast de uitkomst van de voorspelde referentiewaarde in de schoolrapportages wel infoboxen die aangeven waar de voorspelde referentiewaarde van afhangt in de analyse. Deze teksten starten standaard met de zinsnede ‘welke kenmerken versterken/beïnvloeden de kans’, gevolgd door een opsomming die gaat als ‘Hoe lager het percentage leerlingen met een niet-westerse migratieachtergrond op een school, des te hoger de kans…. Hoe hoger het percentageleerlingen uit eenoudergezinnen hoe lager de kans… Hoe hoger het percentage leerlingen uit een gezin met een hoog inkomen hoe groter de kans..’. Dit soort teksten geven scholen de valse associatie dat dit factoren zijn waarmee je uitkomsten kunt verklaren of begrijpen. We kunnen alleen maar hopen dat de bespreking van dit soort rapporten, in bijvoorbeeld een medezeggenschapsraad, niet al te vaak aanleiding heeft gegeven tot even zinloze als ongemakkelijke discussies.
Hangt de voorspelde referentiewaarde af van de gekozen variabelen?
Toen ik mijn bevindingen op ScienceGuid publiceerde, luidde de reactie van NCO: Uitkomst Nationaal Cohortonderzoek verandert niet door meten opleidingsniveau ouders. Hiervoor zochten ze voor een beperkt aantal prestatie-indicatoren uit dat de correlatie tussen de uitkomsten afkomstig van analyses met en zonder het opleidingsniveau van de ouders tussen de 0,88 en 0,99 uitkwam. Een correlatie >0,8 wordt in de sociale wetenschappen gezien als een sterk verband tussen variabelen.
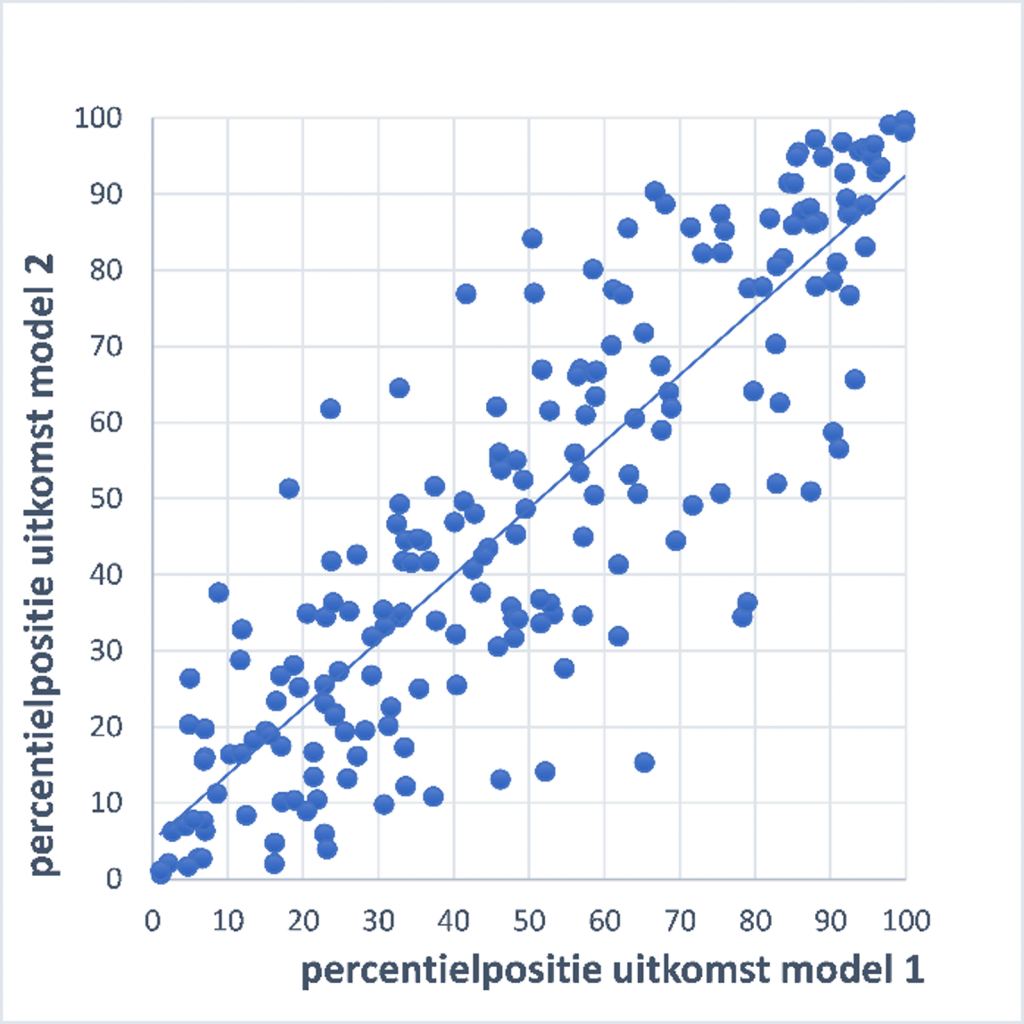
Als het gaat om een correlatie tussen analyse-uitkomsten met verschillende modellen en waarmee op individueel schoolniveau een referentieniveau wordt vastgesteld, ontstaat een ander beeld. In onderstaande figuur kun je zien hoe de uitkomsten op basis van de twee modellen bij een correlatie van 0,88 verschillen, wanneer deze, net als in de NCO-rapportage, worden weergegeven op een percentielschaal. Bij het ene model kan de voorspelling bijvoorbeeld zijn dat het referentieniveau op percentiel 40 zit en bij het andere model is de dat percentiel 78. Het statement van NCO dat de uitkomst van de voorspelde referentiewaarde niet verandert als je het opleidingsniveau van de ouder meeneemt kan dus wel enige nuancering gebruiken.
Leergroeirapportages
Alle basisschoolleerlingen en hun ouders krijgen in Nederland te maken met een leerlingvolgsysteem (LVS) dat de basisvaardigheden volgt. De scores die leerlingen op LVS-toetsen behalen, worden omgezet op een doorlopende schaal van vaardigheidsscores. Deze informatie kunnen scholen delen met NCO, dat het zowel gebruikt voor landelijk onderzoek als om scholen gepersonaliseerde leergroeirapportages terug te geven. Tijdens de COVID-crisis gaf deze database natuurlijk veel nuttige informatie om de impact van lockdowns op onderwijs te te onderzoeken.
Verschillende startniveaus
Leerlingen stromen met zeer verschillende startniveaus en ondersteuning het onderwijs in. Daarom kiest NCO ervoor om de leergroei van subgroepen en scholen voor en tijdens de COVID-crisis te vergelijken en niet de gemiddelde scores per leerjaar. Leergroei is echter een gemiddelde van de verschil-scores van de vaardigheidsscores van leerlingen op twee momenten. Hierbij liggen bijdragen van regressie naar het gemiddelde toe (of juist van het gemiddelde af als de verdeling breder worden) ook weer op de loer. De invloed van regressie naar het gemiddelde op de leergroei wordt bepaald door alle invloeden die willekeurig verlopen (dus evenveel omhoog als omlaag). Hier valt dus ook de betrouwbaarheid van de toetsing zelf onder.
Het effect van regressie naar het gemiddelde zou moeten zijn, dat de prestatieverschillen tussen subgroepen verkleinen in de loop der jaren. Maar dat gebeurt duidelijk niet. De prestatieverschillen blijken uit andere rapportages juist min of meer constant te blijven. Hier zat voor mij iets paradoxaals in, wat ik heb uitgewerkt in dit artikel. In mijn LinkedIn nieuwsbrief werkte ik dit nog verder uit
Leergroeiparadox
De leergroei-paradox wil het volgende zeggen:
Groepen van leerlingen met gemiddeld lagere scores op voortgangstoetsen maken gemiddeld juist veel leergroei door, maar lijken desondanks nauwelijks dichter bij de groep van hoger scorende leerlingen te komen.
Deze paradox kun je als volgt beschrijven. De leergroei van een (sub)groep is het gemiddelde van de leergroei van veel leerlingen. Niet ieder jaar hebben dezelfde leerlingen de hogere leergroei. Bij veel willekeur/toeval in de relatie tussen vaardigheidsscores op verschillende momenten zal voor individuele leerlingen na hogere leergroei veelal weer lagere leergroei volgen en zullen er niet vaak leerlingen uit de groep blijvend ver boven het gemiddelde uitstijgen. Veel docenten kennen het uit de praktijk: de resultaten van leerlingen die hoog zijn blijven meestal ook hoog. Voor een groep leerlingen met een hogere vaardigheidsscore is er dus minder regressie naar het gemiddelde dan voor leerlingen met een lagere vaardigheidsscore. Voor de groep leerlingen die laag scoren is hun vaardigheidsscore dus minder voorspellend voor de score op de volgende toetsen. Hogere gemiddelde scores op een school gaan dus meer over een hoog/hoger niveau vasthouden (wanneer het zich gevormd heeft) en niet zo zeer over leergroei. Voor subgroepen /scholen met de hoogste gemiddelde scores is de gemiddelde leergroei immers veelal het laagst.
Leergroeivertraging tijdens lockdowns
Tijdens de COVID-crisis in 2020 was de gemiddelde leergroei tussen februari en juni lager dan in andere jaren. NCO realiseerde zich waarschijnlijk ook dat verschillen in het effect van de lockdown op verschillende groepen leerlingen niet kon worden opgemaakt door de leergroei te vergelijken. Deze verschilt per slot van rekening altijd al. Tijdens de COVID-crisis stapte NCO daarom over naar leergroeivertraging. Deze leergroeivertraging wil zeggen dat de toename in gemiddelde vaardigheidsscore tussen twee toetsmomenten (bijvoorbeeld tussen februari en juni) minder groot is geworden. Dit werd vervolgens uitgedrukt als een procentuele afname (nieuw-oud/oud). Dit is echter een ingewikkelde en indirecte vergelijking, die nog niet direct aangeeft hoe het effect van de lockdowns uitpakte voor de verschillende groepen.
Of de verschillen tussen gemiddelde vaardigheidsscores van bijvoorbeeld leerlingen van ouders met hoog- en laag sociaaleconomische status toenamen tijdens de COVID-crisis kun je eenvoudig direct vaststellen. Hiervoor kun je kijken of de verschillen tussen de gemiddelde scores tussen deze groepen groter zijn geworden (rekening houdend met de spreiding van de scores). Ik onderzocht de trends in de verschillen tussen de prestaties van jongens en meisjes (Hoe Jip en Janneke examen doen – ScienceGuide). Deze simpele berekening ontbreekt bij het onderzoek naar de effecten van de lockdowns. We kunnen het ook niet zelf afschatten, want nergens worden gemiddelden en standaarddeviaties gepresenteerd van de vaardigheidsscores van de verschillende groepen.
Het ingewikkelde met leergroei
Een hogere leergroei op een school kan, zeker als je dit ieder leerjaar opnieuw tussen juni- en februari-toetsen bekijkt, op totaal verschillende manieren tot stand komen. Leergroei is een verschil-score en deze kan hoger zijn dan bij andere groepen als het startniveau lager is (omdat ze bij de eerste toets veel vergeten zijn van de periode daarvoor) en het eindniveau in de buurt van het gemiddelde (door regressie naar het gemiddelde). Een hoge leergroei kan ook betekenen dat leerlingen een hoger startniveau hebben en dat ze daarbovenop ook nog meer bijleren.
In de praktijk blijken dat de beter presterende subgroepen gemiddeld juist een lagere leergroei hebben. Dit komt mogelijk door een remmende bijdrage van regressie naar het gemiddelde op de leergroei die dan overheerst. Dus de vraag of je nu blij moet zijn, of juist niet, met een gemiddeld hogere leergroei per leerjaar in je schoolrapportage is niet zo gemakkelijk te beantwoorden. En dat geldt dus ook of voor de vraag of het nu gunstig is, of juist niet, als je met de leergroei op een school hoger uitkomt dan de door NCO berekende voorspelde referentiewaarde voor de leergroei. En omdat op groepsniveau leergroei al zo moeilijk te duiden is, dan lijkt het mij dus nog moeilijker om verschillen tussen groepen in leergroeivertraging te interpreteren.
Het venijn zit in de staart
Eerlijk gezegd ben ik bang dat het niet direct duidelijk is dat de verschillen tussen de gemiddelde vaardigheidsscores van verschillende groepen significant groter zijn geworden door de COVID-crisis. De verschillen in gemiddelde leergroeivertraging zijn namelijk relatief klein ten opzichte van de grote verschillen tussen gemiddelde vaardigheidsscores die er voor sommige onderzochte subgroepen altijd al waren. Dit hoeft echter helemaal niet te betekenen dat er niet subgroepen en/of scholen zijn waar de effecten van de lockdowns op de leerontwikkeling van leerlingen veel ingrijpender was. Je moet hierbij bedenken dat een kleine gemiddelde leergroeivertraging veroorzaakt kan worden doordat een deel van de leerlingen ongeveer dezelfde leergroei, of zelfs meer leergroei, doormaakt, terwijl bij een ander deel de leergroei tot stilstand is gekomen of zelfs achteruitging. Het venijn van de ongelijkheid tussen groepen zit mogelijk juist in het scheef worden en verbreden van de scoreverdelingen en niet zo zeer in een verschuiving van het gemiddelde. Ook binnen iedere gedefinieerde subgroep zijn allerlei vormen van heterogeniteit aanwezig. Die kunnen we niet verklaren vanuit de achtergrondkenmerken die toevallig in de database staan.
Doorgeslagen meetwoede
In het Nederlandse onderwijs wordt uitzonderlijk veel gemeten. Deze meetgegevens zouden ons inzicht kunnen verschaffen over hoe op verschillende scholen voor verschillende groepen en onder verschillende omstandigheden de leervoortgang van de basisvaardigheden verloopt. Dit gaat echter alleen wanneer het voor iedereen duidelijk is waar nu eigenlijk naar gekeken wordt. We moeten goed opletten dat al die onderwijsmeetwoede niet doorslaat. Voordat scholen worden gebombardeerd met voorspelde referentieniveaus zou eerst eens onderzocht kunnen worden of scholen hier beter van worden, of dat het alleen maar interessant is om te kijken of je boven of onder je referentieniveau uitkomt. Wat dat dan ook waard is of betekent. Persoonlijk denk ik dat meer spectrale analysevormen van de datamatrix een nuttige aanvulling kunnen zijn. Dat soort analyses geven een beeld van de structuren in de data, zonder dat het direct een oordeel oproept. Dan kunnen we echt gaan nadenken over wat de staat is van het onderwijs.
Credits
Hoofdfoto: Timpaan Onderwijs











Add comment