
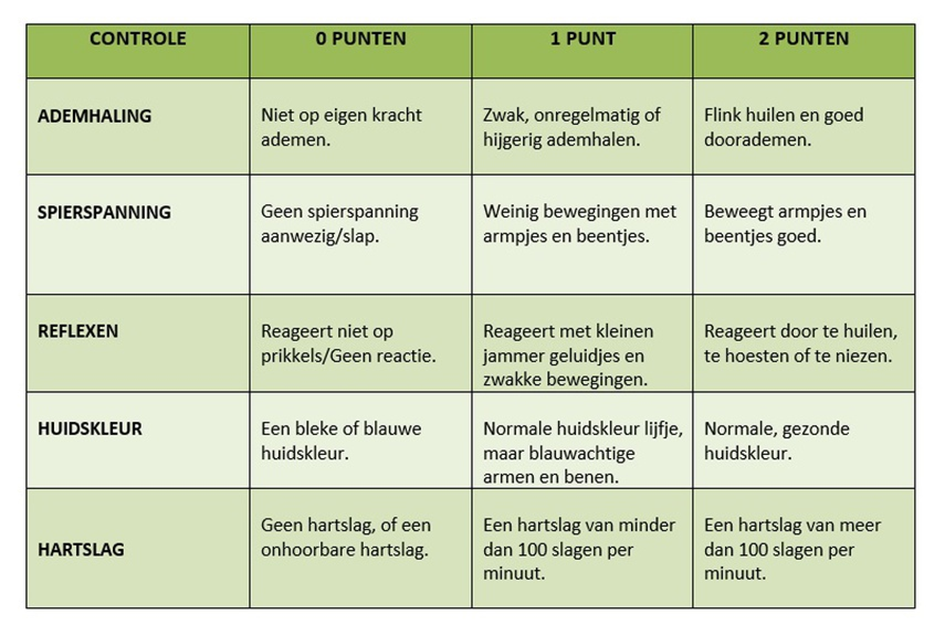
Ben jij in het ziekenhuis geboren? Of misschien jouw kind? Grote kans dat er dan, zonder dat je het wist, een medisch algoritme is gebruikt: de APGAR score. De APGAR score is een eenvoudig model dat in ongeveer 30 seconden bepaalt of pasgeborenen gezond lijken te zijn.1 Denk aan de aanwezigheid van ademhaling, beweging, hartslag of de kleur (blauwig of niet). Als de score laag is, is dat reden om extra op de baby te letten of direct in te grijpen. Als de score hoog is, dan lijkt het in orde. Eventueel wordt de score later nog herhaald. Het is zo vlug toepasbaar en briljant in zijn eenvoud dat de meeste ouders het niet eens doorhebben! Maar hoe wordt zo’n score eigenlijk ontwikkeld?
Wat heb je nodig om iets te kunnen voorspellen?
Eigenlijk kun je alleen voorspellen op basis van eerdere observaties. Die laten zien of bijvoorbeeld de blauwige baby later inderdaad een ademhalingsventilator nodig had. Sommige typen voorspellingen kijken niet naar het verleden. Neem nou het voorbeeld om op basis van biomedische kennis te voorspellen waar moleculen zullen binden om te kijken of een nieuw middel nuttig kan zijn voor een bepaalde ziekte. Hierbij komt een totaal ander type voorspellen om de hoek kijken. Maar, voor de meeste voorspellingen in de wereld waarin we leven, geldt het basisprincipe dat er echte waarnemingen beschikbaar moet zijn. Dit noemen we empirisch bewijs, of data.
Stel dat we een jaar lang data van baby’s verzamelen: hun ademhaling, hartslag, blauwige kleur en of er later behandelingen nodig waren. Daarna kan het rekenen beginnen. Voor mensen is dit lastig. Het lukt een arts wel om na ervaringen met vele baby’s waarschijnlijk goed in te schatten of de blauwige baby daadwerkelijk de ventilator nodig gaat hebben. Het wordt flink ingewikkelder als de arts daar meerdere factoren bij betrekt: wat als de baby een gezonde kleur heeft, maar niet beweegt? Of wel ademt en beweegt, maar blauwig is? Dat maakt het een stuk lastiger. Ook is dit oordeel behoorlijk subjectief: artsen zullen van mening verschillen, wat in dit voorbeeld moeilijk te begrijpen is voor de ouders. Zij willen een heldere beslissing. Gelukkig biedt de computer uitkomst. Op basis van statistische modellen kunnen we rekening houden met al die factoren, en deze afwegen tegenover elkaar. Dit is op basis van het empirische bewijs (de eerder verzamelde data), niet omdat de ene arts toevallig meer blauwige baby’s ter wereld heeft gebracht dan de andere.
Ditzelfde principe gebruikt Mark van der Wiel als hij de rankings van de Top 2000 voorspelt aan de hand van de edities van voorgaande jaren. Want de kunst van het voorspellen beperkt zich natuurlijk niet tot het ziekenhuis: je vindt het overal!
Voorspellende algoritmes zijn overal
Bekende toepassingen van voorspelmodellen hebben gemeen dat ze voor velen nuttig zijn en makkelijk interpreteerbaar, zoals de APGAR score. Dat geldt ook voor het weer! Een eenvoudige voorspelling zoals de kans dat het gaat regenen in de komende drie uur, kan je een nat pak schelen. Zelfs de visualisaties van hoe wolken zich de komende tijd gaan bewegen (bijvoorbeeld op de bekende site www.buienradar.nl) zijn niets meer dan afleidingen van waar de wolken nu staan, plus alle factoren die de wolken bepaalde kanten uit kunnen sturen.
Aardbevingen zijn een stuk lastiger te voorspellen. Dit komt door de complexe samenhang van vele factoren die een aardbeving doet ontstaan, die bovendien veelal lastig of inaccuraat te meten zijn.2 Seismische activiteit is een belangrijk deel van dit verhaal, maar tegen de tijd dat daaruit duidelijk blijkt dat er iets mis is, is het waarschijnlijk al te laat. Een belangrijk verschil met weersvoorspellingen is dat het gevolg van de voorspelling, en dus ook een fout daarin, ernstige gevolgen kan hebben. Stel dat het model mist dat er volgende week midden in Tokyo, Japan een ernstige aardbeving plaatsvindt. De schade en het leed zal enorm zijn… Je wilt dus zekerder van je zaak zijn dan bij het voorspellen van regen. Dat geldt ook voor veel medisch onderzoek, bijvoorbeeld over beslissingen voor fertiliteitsbehandelingen, waar ik onderzoek naar heb gedaan (zie ook mijn vorige blogsposts). Maar daarover later meer.
Een laatste voorbeeld is het voorspellen van beurskoersen. Wanneer kan je het beste in aandelen investeren? En in welke dan? Laat je niet gek maken door degenen die roepen dat ze dit kunnen: de harde waarheid is dat het gewoon erg lastig te voorspellen valt.2 De economie is grillig en van vele factoren afhankelijk, waarvan veel niet eens te meten vallen, zodat je ze ook niet in het model kunt stoppen (bijvoorbeeld of corona in 2020 zou toeslaan, of 2019, of 2021). Zoek je bewijs? De beurs kent veel meer milde verliezers dan grote winnaars. Dat zal de meeste deelnemers van loterijen bekend in de oren klinken. Daarnaast zijn de grootste winnaars vaak de personen die met het meeste geld starten, en zich daardoor heel andere strategieën en marges kunnen veroorloven . Zie ook de hype rondom GameStop (GME). Een kip-met-gouden-eieren voorspelmodel voor de economie bestaat niet, en zal misschien wel nooit bestaan, omdat het gebruik ervan de koersen en economie weer zal beïnvloeden.
Eenvoud versus accuratesse
Wat maakt een goed voorspelmodel? Dat hangt natuurlijk af van waar het voor bedoeld is. In ieder geval moet het resultaat een beslissing informeren: kan de baby naar huis of kunnen we deze beter nog wat langer in het ziekenhuis houden? Moet ik een regenjas aan of niet? Is dit een goed moment om aandelen Tesla te kopen?
Soms is het van belang dat het vlug toepasbaar is, waar eenvoud soms zelfs belangrijker is dan accuratesse. Denk maar aan de APGAR score: na 30 seconden moeten verloskundigen weten wat ze moeten doen. Voor een kweekje in het lab is gewoon geen tijd.
Soms is complexer juist beter, zonder dat dat het beoogde gebruik in de weg zit. Denk aan de weersvoorspelling: deze data is ongelooflijk ingewikkeld, maar omdat het allemaal automatisch wordt verwerkt om nieuwe voorspellingen te maken voor morgen en overmorgen, maakt dat niet echt uit. Dat vindt allemaal ‘achter de schermen’ plaats, het real-time resultaat is nu eenvoudig bruikbaar. De context bepaalt dus de invulling en het gebruik van voorspelmodellen.
Dus, hoe voorspel je de toekomst? Met het verleden.
Het kan enorm nuttig zijn om op basis van wat is geweest, proberen te voorspellen wat er gaat komen. De toepasbaarheid is eindeloos: van het weer tot rampen tot het ziekenhuis (jammer dat het bij de economie nog niet echt lukt). In het ziekenhuis kan het misschien wat onmenselijk overkomen, die afhankelijkheid van machines, maar de ironie is dat juist het zakelijke en objectieve van de computer in veel gevallen betere voorspellingen oplevert dan die van artsen of andere experts. Dat is helemaal niet zo verbazingwekkend: mensen maken nu eenmaal fouten. En gezien de gevolgen van het stellen van een verkeerde diagnose of het starten van de verkeerde behandeling, willen we dat liever beperken. Dan maar uitvoeren wat de computer adviseert. Al laat ik mijn financiële beslissingen daar liever niet van afhangen…
Bronnen:
1. APGAR score: zie bijvoorbeeld https://www.youtube.com/watch?v=98ikG8a9JKs&ab_channel=Medzcool.
2. The Signal and the Noise, boek over voorspelmodellen geschreven door Nate Silver.
Hoofdfoto: Manfred Legasto Francisco op Pexels.com
Lees ook:











Add comment