
AI wordt steeds vaker gebruikt om medische voorspelmodellen te maken. De gedachte is vaak: als we maar genoeg data hebben, dan zal AI alle patronen kunnen ontrafelen. Dit is een mythe. Ook AI kan verdrinken in de ‘noise’.
Het WK voetbal is in volle gang. Daarom gaf een vriend me recent het zeer aan te bevelen boek Don’t mention the VAR# van techfilosoof Rens van der Vorst. Zijn punt: vaak wordt de technologie als uitgangspunt voor de oplossing genomen i.p.v. het eigenlijke probleem zelf. En daarbij schuwt hij parallellen met overmatig gebruik van technologie, inclusief AI, in de samenleving bepaald niet.
AI-voorspellingen in de medische wereld
Ik zie veel onderzoeksvoorstellen over voorspelmodellen gebaseerd op AI. Daar zitten soms echt goede ideeën tussen. Maar het gevoel van Van der Vorst bekruipt mij vaak ook: het gaat vaak meer over de technologie – hier AI gecombineerd met bakken met data – dan over een duidelijke strategie die het probleem zou kunnen oplossen.
Hoe zit dat in mijn eigen omgeving, een academisch ziekenhuis? Ik wil geen ouderwetse statisticus zijn, dus ook ik gebruik en ontwikkel samen met collega’s AI-voorspelmodellen. Deze kunnen immers automatisch complexe niet-lineaire verbanden representeren. Maar wij vergelijken ze dan wel altijd wel met een saai lineair regressiemodel. En vaak zien we dat die laatste qua voorspelvermogen zelden onderdoet voor de complexe AI-modellen, terwijl het veel makkelijker te interpreteren is. Mijn gedachte was vaak: “als we maar meer data krijgen om het voorspelmodel te trainen, dan wordt AI vanzelf beter”.
Tot een recent artikel$ mijn ogen opende: meer data helpt lang niet altijd! Schulz & Ritter maken haarfijn duidelijk dat als de voorspellende variabelen (bijv. bloedwaarden, genetica, MRI-beelden) een behoorlijke meetfout bevatten, er vaak niets te winnen valt met AI-modellen, ook al bestaan die niet-lineaire relaties in werkelijkheid echt. Figuur 1 geeft de intuïtie hierachter weer: het verband wordt overschaduwd door de meetfout en de beste fit is dan (vrijwel) lineair. Daarnaast laat het figuur ook zien dat die fit nauwelijks verandert met data van 10x meer patiënten. Maar de fit verbetert wel degelijk als we metingen voor 100 patiënten middelen over 10 herhalingen, want daarmee wordt de meetfout kleiner.
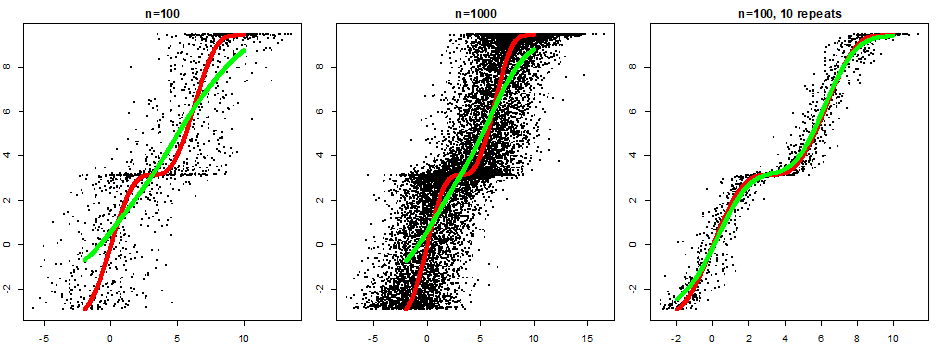
Wat is die meetfout?
Tja ‘meetfout’. U denkt vast: “Ho even, die meetfout valt toch wel mee voor veel moderne medische meetinstrumenten?” Klopt, de pure technische meetfout (de afwijking wanneer de meting onder exact dezelfde condities wordt herhaald) wel. Maar helaas, de algehele meetfout bevat ook iets dat veel moeilijker te reduceren is: de biologische variatie binnen één patiënt. Variatie over tijd en locatie spelen daarbij een grote rol. Een voorbeeld. Vaak wordt van een tumor één biopt genomen om daarvan een genetisch profiel te bepalen. Daarmee worden dan legio AI-voorspelmodellen ontwikkeld. Maar het is bekend dat tumoren genetisch behoorlijk heterogeen kunnen zijn. Dus men meet met potentieel een grote meetfout. En AI gaat dat niet verhelpen. Meer metingen per patiënt mogelijk wel (zie Figuur 1, rechts), maar dat is kostbaar, tijdrovend en moeilijker te analyseren. Dus dat wordt vaak niet gedaan, helaas.
Als we willen dat AI betere voorspellingen gaat doen – en dat willen we – dan moeten we alles-op-alles zetten om die biologische variatie binnen één patiënt goed in kaart te brengen. Dat zijn misschien niet de meest spannende studies, maar wel zeer waardevol. Dus om het probleem (accurate voorspellingen) echt op te lossen, moeten we niet alleen nadenken over de technologie – welke AI laten we los op een grote bak met data – maar meer nog over wát er in die bak met data moet zitten.
Bronnen
#Rens van der Vorst (2026). Don’t mention the VAR. WK editie. Bot Uitgevers.
De meetfout komt ook terug in dit boek. Zelfs voor de behoorlijke kleine meetfout van de moderne VAR-systemen maakt de auteur duidelijk dat een zogenaamd precieze ‘call’ (ook nog ondersteund met een animatie) helemaal niet wenselijk is.
$Marc-André Schulz, Kerstin Ritter (2026). Measurement noise limits the advantage of nonlinear models over linear models in biomedical prediction. Arxiv: https://arxiv.org/abs/2606.18420
Verdrinkende AI Figuur: ChatGPT











Add comment