Yes, Quantification Learning, algorithms that count objects. Initially, it seems not too different from the machine learning task called classification. In classification, we train an algorithm to give each new data point a label. For example, is this e-mail spam or normal? The aim of quantification learning is to calculate the percentage of estimated labels in a data set. So, instead of classifying each e-mail, we are only interested in the number of spam messages of your received e-mails last week. Easy, right? I thought the same and I hear you thinking: “Why is this a separate research area? Quantification seems much easier than classification. Is that really a problem?”
A balancing act
Let’s start with the obvious: a perfect classifier is also a perfect quantifier. If we can classify each of your e-mails correctly whether it is spam or not, then we compute the correct number of spam emails in an inbox. However, the perfect classifier unfortunately does not exist. They all make mistakes, one more than the other. Let’s move on to a more spicy statement: a worse classifier can be a better quantifier. That sounds somehow paradoxical. Let me explain this statement using two models.
We start with the basic model. This model makes a total of 20 mistakes: 10 mistakes are false positives and 10 are false negatives. A false positive is in this case falsely labelling normal mail as spam mail. On the other hand, a false negative is classifying spam mail as normal mail. Using some fancy neural network, we are able to reduce the number of misclassifications. The new model only makes 8 mistakes, whereof 2 false positives and 6 false positives. Obviously, the improved model is the better classifier, but is it also a better quantifier? I don’t think so!
The simple model is better for quantifying since the mistakes cancel each other out. In the improved model, the number of errors differs in both groups. Normal mail is more often labelled incorrectly than spam mail. Consequently, we overestimate the total number of spam emails. From this example, we can conclude that balancing the errors is way more important than minimalizing the errors. But still, is that really a problem?
AI-lection
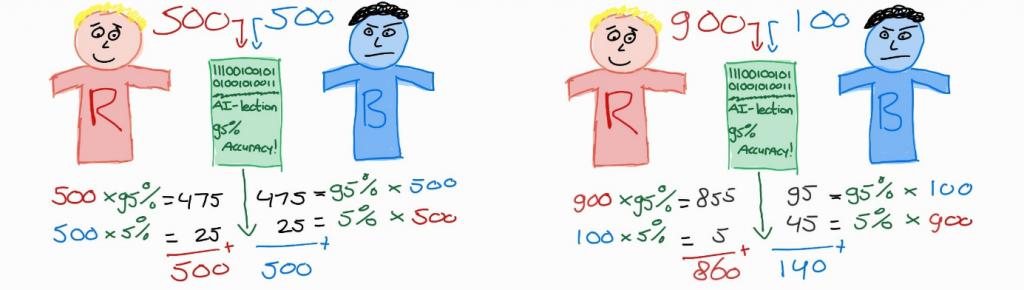
Balancing the errors is harder than you think. We illustrate the problem with an algorithm that estimates the number of votes on two parties: the Reds and the Blues. The model AI-lection is trained to predict the vote of a citizen quite accurately. In a new city, the algorithm can predict 95% of the citizen’s votes correctly, regardless of which party they vote for. We use AI-lection to estimate the number of party votes in two cities (Figure 1).
In the left city, it is a neck-to-neck race between the Reds and the Blues. Both parties end up with 500 votes from their voters. The algorithm has predicted the outcome well, the mistakes are nicely distributed over the parties and we get a perfect prediction. Great! We will use AI-lection in the right city next.
There is less competition here since 900 citizens have voted for the Reds and only 100 for the Blues. AI-lection made quite a mistake. The algorithm underestimates the win of the Reds. Instead of 90 percent, they are predicted to get 86 percent of the votes. The Blues are predicted to obtain 14 percent of the votes, instead of the 10 percent that voted for them. Even though the classification accuracy of AI-lection is equal in both cities, the quantification accuracy differs substantially. The true percentage of voters for a party impacts the algorithm’s performance. And yes, that’s a problem!
Upcoming field
I hope that this blog has convinced you that classifying and counting is not as accurate as you might think. The main problem is that classification accuracy says nothing about the accuracy of counts. How the counts are divided over the groups is a crucial parameter to decide the accuracy. And that crucial parameter is the one we want to estimate in the wonderful world of Quantification Learning!
Even though classification is well-settled in the world of statistics, Quantification Learning is relatively new and it needs some more popularity. If we stare blind on classic classification algorithms, extreme biases can occur in quantifying counts. There’s only a handful of scientists doing research in this field and the Wikipedia page only exists for a few months. And that is strange for one of the most fundamental elements in mathematics: counting. How interesting!











Add comment